
Children's vowel database
Peter Assmann, Daniel Hubbard, Sneha Bharadwaj, Sarah Levitt, Santiago Barreda, Terrance Nearey
With support from the National Science Foundation, we are developing a database of speech recordings from children between the ages of 5 and 18 years from the Dallas, Texas region. These recordings provide the materials for constructing stimuli in a series of listening experiments, and serve as the basis for acoustical and statistical analyses that will test and refine hypotheses about the perceptual transformations used by listeners to cope with acoustic variability in speech perception. The measurements are used to develop acoustic models of age-related changes in children’s speech that can serve as the basis for realistic voice synthesis and allow us to generate predictions of listeners’ judgments in listening tests.


Indexical properties in speech
Peter Assmann, Daniel Guest, Michelle Kapolowicz, Santiago Barreda, Terrance Nearey
In addition to linguistic information, speech contains information about the physical characteristics of the talker, including sex, age and size. These “indexical properties” are associated with the same acoustic cues that are involved in vowel identification. In spite of their common origin and shared cues, the perceptual mechanisms involved in the perception of talker size, age, and sex have for the most part been studied separately from the mechanisms involved in phonetic perception and speech intelligibility. The connection between phonetic properties and indexical information deserves careful investigation. Several theories of talker normalization propose that listeners make use of indexical properties to map the phonetic space of the talker. Pattern classification studies have indicated that vowels are identified more accurately if speaker sex information is included (and vice versa). To determine how perceptual mechanisms exploit this interdependency, we are conducting experiments to study the relationship between judgments of speaker age, sex and vowel quality/speech intelligibility.
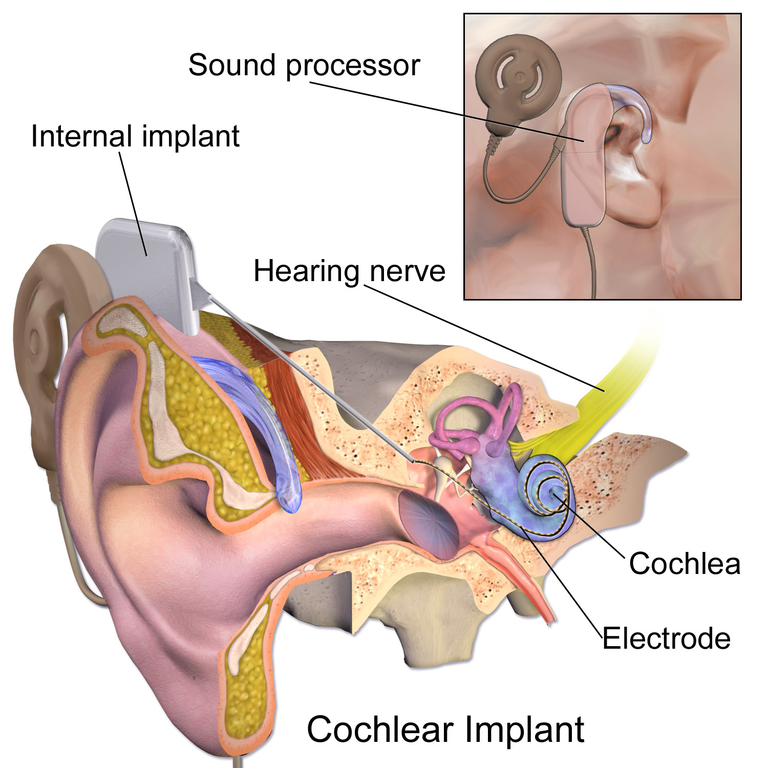
Cochlear implants
Shaikat Hossain, Vahid Montazeri, Olga Peskova, Daniel Guest, Adrian Cho
Our research with cochlear implants (CIs) spans a number of areas, including: Speech perception, development of speech production, perception of voice gender, music perception, spatial hearing, computational approaches to speech enhancement, and auditory modeling. One of our main focuses is studying the effects of noise and reverberation on speech intelligibility in CI users. Many of our experiments make use of acoustic simulations of CI processing based on channel vocoders.

Foreign-accented speech
Michelle Kapolowicz, James Kuang, Vahid Montazeri
Listeners comprehend speech reliably despite variability in speaking rate or speaker size and sex. However, speech perception becomes more challenging if the speaker has a foreign accent or the listener must contend with background noise. Our lab is currently investigating the interaction between these two sources of perceptual distortion to better characterize the time course and underlying mechanisms of listener adaptation. Our findings may help understand and enhance the perception of foreign-accented speech in real life scenarios such as learning in classrooms, performance of automatic speech recognizers, and second language instruction.

Emotional expression
Peter Assmann, Daniel Hubbard
Current diagnostic tools for autistic spectrum disorder (ASD) consist of qualitative assessments of emotional speech function administered by a clinician or caregiver. We aim to quantify the acoustic differences between typically-developing talkers and those with ASD to better understand abnormal patterns of communication. Our work may contribute to more objective diagnostic tools and training methods to assist talkers with ASD. Results to date reveal systematic differences in emotion production between talkers with ASD and controls. We are beginning to investigate the impact of these differences on emotion perception.
Frequency-shifted speech
Peter Assmann, Terrance Nearey
With support from the National Science Foundation, we have conducted a series of experiments on the perception of frequency-scaled speech (vowels and sentences) using a high-quality vocoder called STRAIGHT. Our experiments showed that vowel identification accuracy remains high when the scale factors are chosen to produce speech sounds that occupy the natural range of human voices. Performance declined with more extreme formant patterns that extended well beyond the observed limits. Identification accuracy was higher when F0 and formants were scaled in a natural manner [for example, a 15 percent increase in spectrum envelope (i.e., formant frequencies) combined with an 80 percent increase in F0, transforming adult male to adult female ranges]. Shifting the formants up in combination with a lowered F0 (and vice versa) led to lower performance. Listeners are thus sensitive to the natural ranges of the formant frequencies and F0, and to their statistical co-variation. Taken together, the findings suggest that listeners have a fairly detailed internal representation of voice properties, including the statistical co-variation of F0 and formant patterns, and this internalized knowledge appears to play a wider role in speech perception than suggested by traditional accounts.