(UTD-MHAD)
Introduction
This dataset was collected as part of our research on human action recognition using fusion of depth and inertial sensor data. The objective of this research has been to develop algorithms for more robust human action recognition using fusion of data from differing modality sensors. (Note: A more recent dataset using the second generation of Kinect camera is provided at this link http://www.utdallas.edu/~kehtar/Kinect2Dataset.zip and its description at http://www.utdallas.edu/~kehtar/Kinect2DatasetReadme.pdf.)
A multiView action dataset is also provided at http://www.utdallas.edu/~kehtar/MultiViewDataset.zip
with a desrciption at http://www.utdallas.edu/~kehtar/MultiViewDataset.pdf
Sensors
For our multimodal human action dataset reported here, only one Kinect camera and one wearable inertial sensor were used. This was intentional due to the practicality or relatively non-intrusiveness aspect of using these two differing modality sensors. Both of these sensors are low cost, easy to operate, and do not require much computational power for the real-time manipulation of data generated by them. A picture of the Kinect camera is shown below. It can capture a color image with a resolution of 640×480 pixels and a 16-bit depth image with a resolution of 320×240 pixels. The frame rate is approximately 30 frames per second.The wearable inertial sensor used here was the low-cost wireless inertial sensor built in the ESSP Laboratory at the University of Texas at Dallas. This sensor consists of (i) a 9-axis MEMS sensor which captures 3-axis acceleration, 3-axis angular velocity and 3-axis magnetic strength, (ii) a 16-bit low power microcontroller, (iii) a dual mode Bluetooth low energy unit which streams data wirelessly to a laptop/PC, and (iv) a serial interface between the MEMS sensor and the microcontroller enabling control commands and data transmission. This wearable inertial sensor is shown in the figure below. The sampling rate of this wearable inertial sensor is 50 Hz. The measuring range of the wearable inertial sensor is ±8g for acceleration and ±1000 degrees/second for rotation.
Kinect camera Wearable inertial sensor


Human Actions in the Dataset
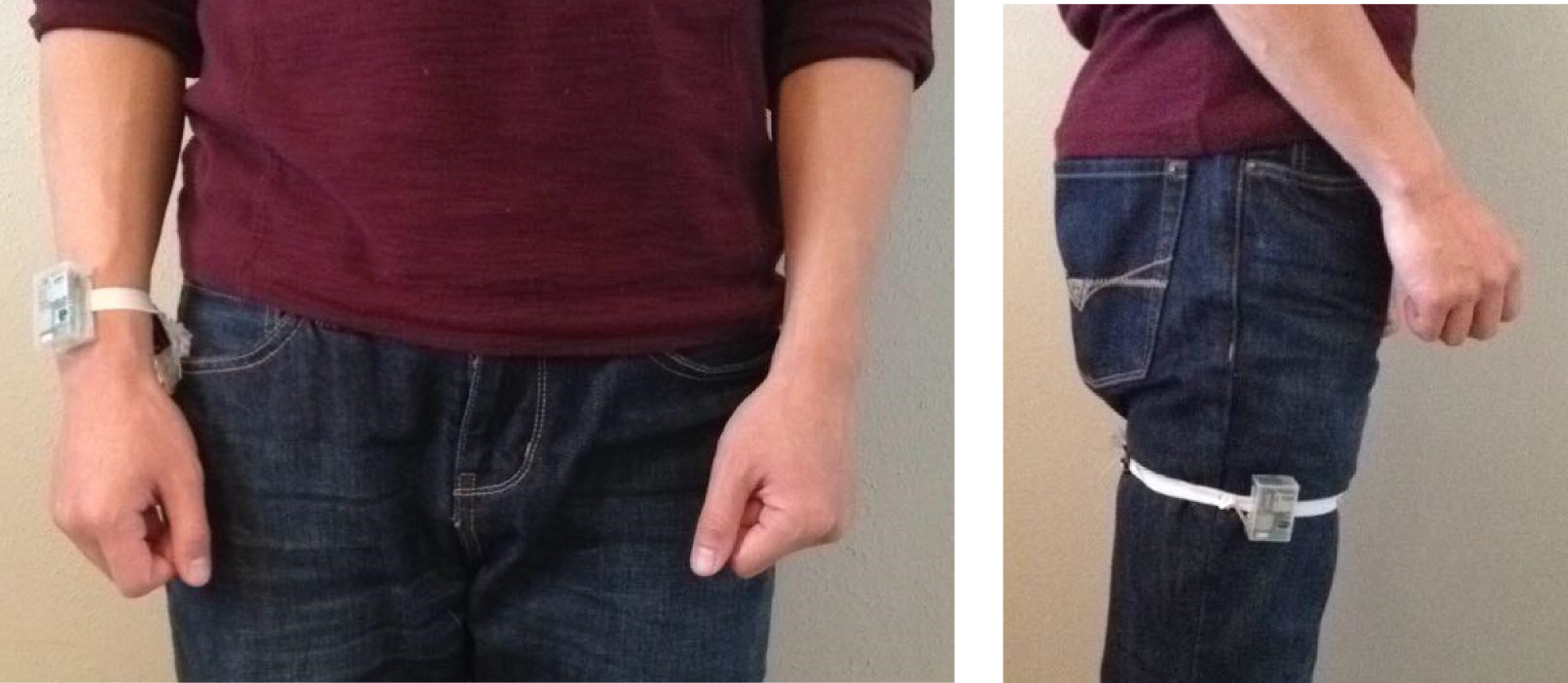
Our UTD-MHAD dataset consists of 27 different actions: (1) right arm swipe to the left, (2) right arm swipe to the right, (3) right hand wave, (4) two hand front clap, (5) right arm throw, (6) cross arms in the chest, (7) basketball shoot, (8) right hand draw x, (9) right hand draw circle (clockwise), (10) right hand draw circle (counter clockwise), (11) draw triangle, (12) bowling (right hand), (13) front boxing, (14) baseball swing from right, (15) tennis right hand forehand swing, (16) arm curl (two arms), (17) tennis serve, (18) two hand push, (19) right hand knock on door, (20) right hand catch an object, (21) right hand pick up and throw, (22) jogging in place, (23) walking in place, (24) sit to stand, (25) stand to sit, (26) forward lunge (left foot forward), (27) squat (two arms stretch out).The inertial sensor was worn on the subject's right wrist or the right thigh (see the figure below) depending on whether the action was mostly an arm or a leg type of action. Specifically, for actions 1 through 21, the inertial sensor was placed on the subject's right wrist; for actions 22 through 27, the inertial sensor was placed on the subject's right thigh.
Example images from the 27 actions:
1. Swipe left 2. Swipe right 3. Wave 4. Clap 5. Throw 6. Arm cross 7. Basketball shoot 8. Draw X 9. Draw circle (clockwise) 10. Draw circle (counter clockwise) 11. Draw triangle 12. Bowling 13. Boxing 14. Baseball swing 15. Tennis swing 16. Arm curl 17. Tennis serve 18. Push 19. Knock 20. Catch 21. Pickup and throw 22. Jog 23. Walk 24. Sit to stand 25. Stand to sit 26. Lunge 27. Squat



























Dataset Description
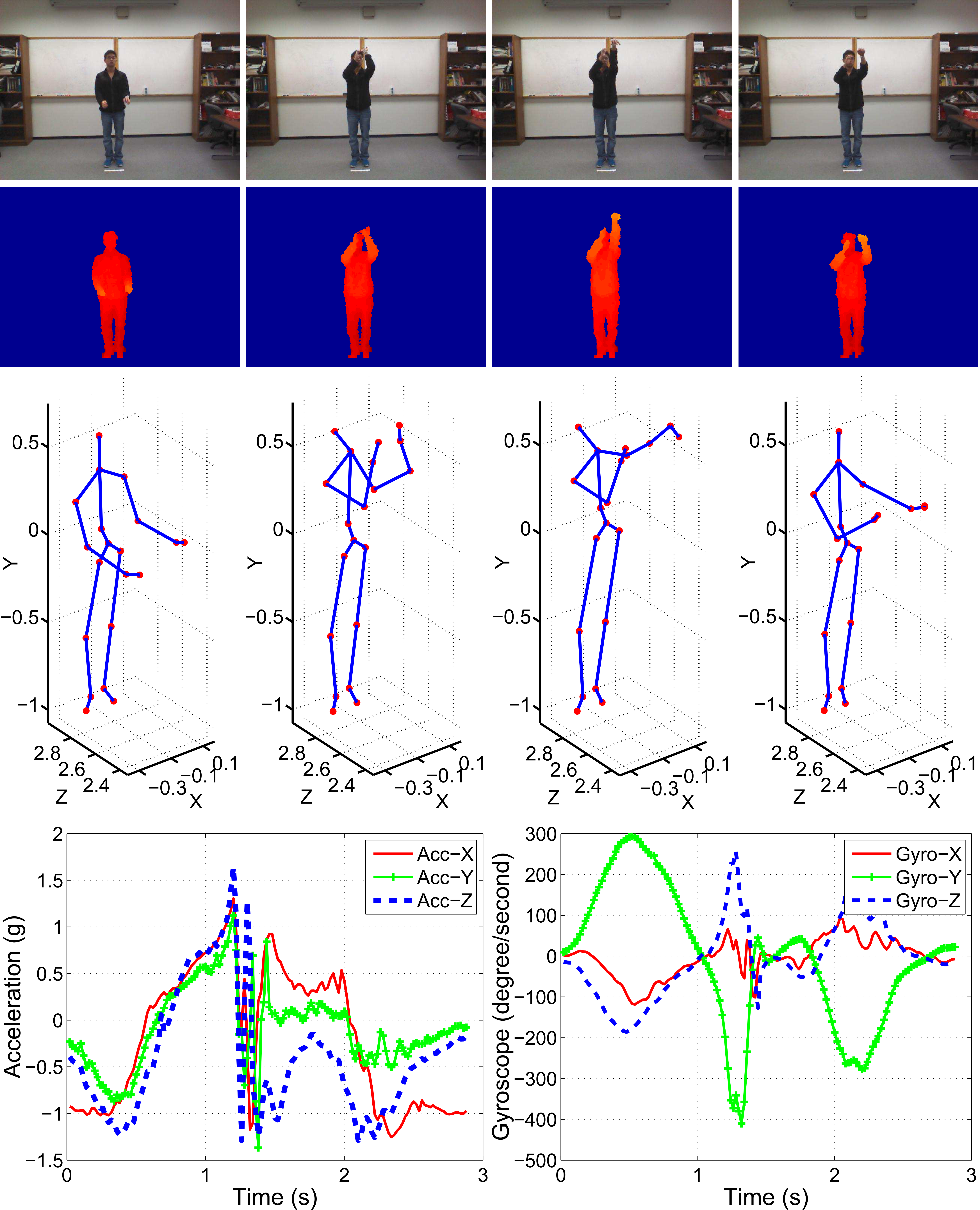
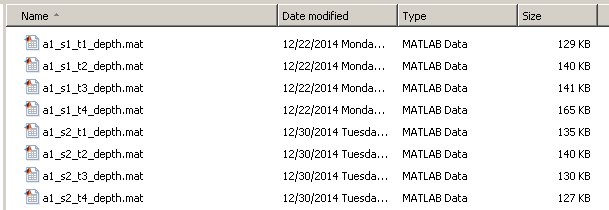
The UTD-MHAD dataset was collected using a Microsoft Kinect sensor and a wearable inertial sensor in an indoor environment. The dataset contains 27 actions performed by 8 subjects (4 females and 4 males). Each subject repeated each action 4 times. After removing three corrupted sequences, the dataset includes 861 data sequences. Four data modalities of RGB videos, depth videos, skeleton joint positions, and the inertial sensor signals were recorded in three channels or threads. One channel was used for simultaneous capture of depth videos and skeleton positions, one channel for RGB videos, and one channel for the inertial sensor signals (3-axis acceleration and 3-axis rotation signals). For data synchronization, a time stamp for each sample was recorded. An example of our multimodality data corresponding to the action basketball-shoot is illustrated in the figure below. For each segmented action trial, the color data was stored in video (.avi) files, and the depth, skeleton and inertial sensor data were stored using the MATLAB computing environment as three .mat files, respectively. As a result, four data files for an action trial are included in the dataset. The naming convention of a file is "ai_sj_tk_modality", where ai stands for action number i, sj stands for subject number j, tk stands for trial k, and modality corresponds to four data modalities (color, depth, skeleton, inertial). A snapshot of the dataset is provided below.
An example of the multimodality data corresponding to the action basketball-shoot. The first row shows the color images, the second row the depth images (the background of each depth frame was removed), the third row the skeleton joint frames, and the last row the inertial sensor data (acceleration and gyroscope signals).
A snapshot of the data files appearing in UTD-MHAD
Download
The dataset files can be downloaded here. A MATLAB package is also provided which allows one to view and use all the data modalities.[RGB_Data.zip (.avi)] [Depth_Data.zip (.mat)] [Skeleton_Data.zip (.mat)] [Inertial_Data.zip (.mat)] [Sample_Code.zip (MATLAB code)]
Citation
The following paper provides more information on the dataset:C. Chen, R. Jafari, and N. Kehtarnavaz, "UTD-MHAD: A Multimodal Dataset for Human Action Recognition Utilizing a Depth Camera and a Wearable Inertial Sensor", Proceedings of IEEE International Conference on Image Processing, Canada, September 2015.
Contact
If you find any errors or problems, please report to Chen Chen (Chen.Chen12@utdallas.edu or chenchen870713@gmail.com).