


Next: Chapter 11: Distributed Scheduling
Up: No Title
Previous: Chapter 3: Process Deadlocks
Goals
- 1.
- Network transparency
- 2.
- High availability
Design Issues
- 1.
- Naming and name resolution
- 2.
- Cache on disk or main memory
- 3.
- Writing policy
- 4.
- Cache consistency
- 5.
- Availability
- 6.
- Scalability
- 7.
- Semantics of file opeations
Case Study: Coda File System
- for large scale distributed computing environment using UNIX workstations
- resiliency to server and network failures
- server replication
- disconnected operation of clients when no server can be contacted
Coda Features
- 1.
- Few trusted servers, many untrusted clients
- 2.
- Clients cache entire files on local disks
- 3.
- Cache coherence by callback: servers notify workstations of
changes to cached files
- 4.
- Clients dynamically map files to servers and cache this information
- 5.
- Token-based authentication and end-to-end encryption
Replication Strategies
- 1.
- Pessimistic: restrict updates to at most one partition
- 2.
- Optimistic: updates allowed in every partition; detect and resolve
conflicts after they occur
Optimistic strategy chosen because:
- 1.
- higher availability
- 2.
- enables support for portable workstations
- 3.
- write sharing between users is relatively infrequent
One-copy UNIX Semantics
Every modification to every byte of a file has to be immediately visible
to every client
- conflicts with stated goals of scalability and availability
- relax the constraint
Lessons from Andrew File System
- 1.
- Propagating changes at granularity of file opens and closes is adequate
for virtually all applications
- 2.
- Slightly weaker consistency guarantees are acceptable: if a callback
from server to a client (or modification of the file by another client) is
lost a client may continue to use a cached copy of the file for some time
after that file has been changed elsewhere
- 3.
- Client maintains information about a subset of servers that are
currently accessible. If this set is empty: disconnected mode of operation.
Server Replication
Volume: unit of replication
- set of files and directories forming a subtree
- unique file identifier (FID) for each file and directory
- Volume Storage Group (VSG):
- set of servers with replicas of a
volume (only a subset, AVSG, may be accessible)
- Volume Replication Database:
- stores the degree of replication and
identity of replication sites of a volume (present at every server)
Strategy
Read-One, Write-All (ROWA)
- before reading verify that server being read (preferred copy) has
latest copy
- if not: (i) change preferred site, (i) inform AVSG about existence of
stale copies
- establish callback with preferred server
- on file close after modification transfer file in parallel to all
servers in AVSG
Cache Coherence
- try to contact missing members of VSG every
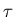 seconds
seconds
- on AVSG enlargement: next reference to any object goes to enlarged
AVSG
- shrinking AVSG:
- detected by probing members every
seconds
- if preferred server gone, drop callback
Cache Coherence (contd.)
- to detect updates missed by preferred server cache manager requests
volume version vector (CVV) for every volume from which it has
cached data
- mismatch in volume CVV indicates some AVSG members have missed
updates
 drop callback
drop callback
Replica Management
- each modification to server tagged with storeid
- server could maintain update history as a chronological sequence of
storeids
- length of update history at every replica maintained by server in CVV
- submissive replica has a prefix of updates at a dominant
replica
- inconsistency
neither replica dominates the other, nor
equal
State Transformation
- Update:
- extends update history; two-phase operation
- Force:
- copying updates from a dominant replica to a submissive replica
- Repair:
- used to return inconsistent replicas to normal use
- Migrate:
- saves copies of objects involved in unsuccessful updates
resulting from disconnected operation for future repair
Next: Chapter 11: Distributed Scheduling
Up: No Title
Previous: Chapter 3: Process Deadlocks
Ravi Prakash
2000-04-22