Approximate Computing
Ongoing • 2016-present•

Many classes of applications exhibit significant tolerance to inaccuracies in their computations.
Some examples include image processing, multimedia applications and machine learning. These inaccuracies
can be exploited to build circuits with smaller area, lower power and higher performance. One of the main
problems with approximate computing is that it is highly data dependent. The resultant micro-architecture
will depend on how aggressively it is approximate and on the training data. Often random inputs are used.
The error can nevertheless reach intolerable levels in case that the final workload significantly differs
from the training data used during the architectural approximation.
The main problem is that most of the previous work on approximate computing focuses on a particular VLSI design level.
Although, leading to promising results, only a subset of all possible optimizations are visible at each level. E.g. some
work in the past has dealt with approximate computing at the behavioral level, focusing mainly on the limitation of the
precision or data type simplification of variables. Moreover, previous work assumes a single input data distribution (IDD)
when approximating the design, often random data is used. In reality the final workload can differ significantly from the IDD used when
approximating the design. It has also been shown, that workloads tend to change over time, hence, this canlead to intolerable error levels.
Key References:
S. Xu and B. Carrion Schafer,
Towards Self-Tunable Approximate Computing IEEE Transactions on Very Large Scale Integration (TVLSI) Systems, pp.778-789, Vol.27(4), 2019.
B. Carrion Schafer,"
Approximate Computing: Mitigating the Risk of Dynamic Workloads", IEEE COMSOC Technology News (CTN), 2017
[html].
S. Xu, B. Carrion Schafer,"
Exposing Approximate Computing Optimizations at Different Levels: From Behavioral to Gate-Level", IEEE Transactions on Very Large Scale Integration (TVLSI) Systems, Vol. 25, Issue 11, pp.3077-3088, 2017.
S. Xu and B. Carrion Schafer,
Approximate Reconfigurable Hardware Accelerator: Adapting the Micro-architecture to Dynamic Workloads, International Conference on Computer Design (ICCD), pp. 1-7, 2017.
B. Carrion Schafer,
Enabling High-Level Synthesis Resource Sharing Design Space Exploration in FPGAs through Automatic Internal Bitwidth Adjustments, IEEE Transactions of Computer Aided Design (TCAD), Volume 36, Issue 1, pp. 97-105, Jan. 2017.
Runtime Reconfigurable FPGAs Optimizations
Ongoing • 2014-present•
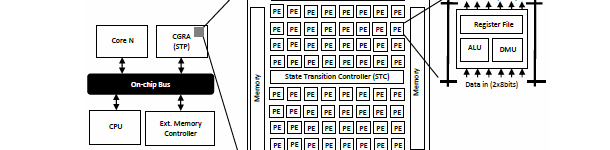
System-on-a-Chip (SoC) which typically include embedded
CPUs, Memory, dedicated HW accelerators and multiple
I/O peripherals can be widely found in consumer electronic
products. They are faster and consume less power than general
purpose solutions and hence are well suited for typical
consumer products applications e.g. cellular phones, DVD
players and portable gaming consoles. The main problem
when designing SoCs is their increasing complexity which
leads to long development times. With the increasing demand
for newer products with more and more powerful features,
new or reviewed versions of the SoCs need to be tapedout
at continuously shorter time frames. This means that
time-to-market, but also time-in-the-market is getting shorter
and hence the risk of not achieving the estimated return on
investment (ROI) grows significantly. One alternative solution
in order to reduce the time-to-market and increase the timein-
the market is to use Reconfigurable (Programmable) SoCs
(RSoCs). These RSoCs include reconfigurable IPs normally
used to accelerate computational intensive function with high
parallelism (e.g image processing or DSP applications).
In order to make CGRAs more efficient they can be runtime
reconfigurable. This implies that an application is synthesized
into multiple contexts which are loaded every clock cycle to
execute a given part of the application mapped onto the CGRA. This project
invesigates how to reduce the total resource usage
at the most atomic level, i.e. the re-use of single
PE across processes. The target is to optimize the resources
at design time in order to reduce the area of the CGRA IP
and not runtime. This project is done in collaboration with Renesas Electronics using their runtime
reconfigurable processor called Stream Transpose
Processor (STP)
Key References:
B. Carrion Schafer, "
Tunable Multi-Process Mapping on Coarse-Grain Reconfigurable Architectures with Dynamic Frequency Control", IEEE Transactions on Very Large Scale Integration (TVLSI) Systems, 2015.
B. Carrion Schafer,
Time Sharing of Runtime Coarse-Grain Reconfigurable Architectures Processing Elements in Multi-Process System, International Conference on Field-Programmable Technology (FPT), 2014
Automatic Fault-Tolerant System Generation
Ongoing • 2016-present•
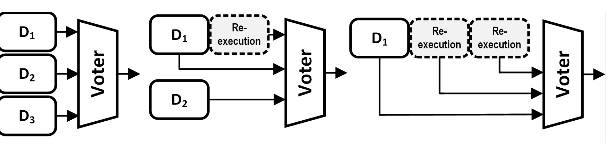
Fault-tolerance can be described as the ability of a system to continue to work after the occurrence of an error.
Fault-tolerant electronic systems are becoming a standard
requirement in many industries ranging from aeronautics to automotive as electronics have become pervasive in many industries.
Shrinking geometries, lower operating voltages, higher operating frequencies and higher density circuits have led to an increase sensitivity towards soft errors. These occur
when a radiation event causes a disturbance large enough to reverse a bit in the circuit. When the bit is flipped in a critical control register or configuration memory, it can
cause the circuit to malfunction
Most previous work on VLSI design reliability is based
around time or space redundancy. In space redundancy, the main idea is to replicate the same channel N times,
also called N-Modular Redundancy (NMR). For larger electronic systems these channels are being built by sourcing parts from different vendors. However in VLSI design, the underlying hardware channel is
exactly the same since it is too expensive to design multiple hardware versions with the same specifications. The Triple Module Redundancy (TMR) is one of the most popular implementations
of NMR systems as it can fully mask errors. This work investigates techniques to generate multiple different micro-architectures from a single behavioral description to find the most reliable TMR system.
Key References:
F. N. Taher, A. Balachandran, Z. Zhu and B. Carrion Schafer,
Common-Mode Failure Mitigation:Increasing Diversity through High-Level Synthesis, Design, Automation, and Test in Europe (DATE), pp.1-4, 2019.
F. N. Taher, Joseph Callenes-Sloan and B. Carrion Schafer,
A machine learning based hard fault recuperation model for approximate hardware accelerators, Design Automation Conference (DAC), pp. 1-6, (accepted for publication), 2018.
F. N. Taher, M. Kishani and B. Carrion Schafer,
Design and Optimization of Reliable Hardware Accelerators: Leveraging the Advantages of High-Level Synthesis, IEEE International Symposium on On-Line Testing and Robust System Design (IOLTS), pp. 1-4, 2018.
A. Balachandran, N. Veeranna and B. Carrion Schafer,
On Time Redundancy of Fault Tolerant C-Based MPSoCs, IEEE Computer Society Annual Symposium on VLSI (ISVLSI), Pittsburgh, July, 2016.
Behavioral IP Protection
Ongoing • 2014-present•
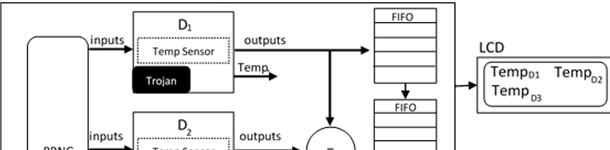
Semiconductor companies were in the past vertically integrated. Companies like IBM, Intel and Samsung, still follow this strategy.
However in the past 20 years the fastest growing semiconductor companies were fabless companies. These design companies focus on the
architectural development of the HW and contract silicon foundries for the manufacturing process. Some examples include Altera,
Broadcom, Cisco, Qualcomm and Xilinx. Due to the cost of setting up their own manufacturing facilities, this trend is predicted to
grow. Even some traditionally vertically integrated companies, have divested their manufacturing facilities (or part of them) e.g. AMD,
Fujitsu, Renesas.
Although from the economical point of view, the horizontal integrated model is sound, it poses many new challenges. This business
model leads to these companies not having control over the manufacturing process and hence do not control e.g. how many ICs the
foundry has actually manufactured and if the design has been maliciously modifed to include e.g. HW Trojan. On the other hand
ITRS suggest that by 2020 a 10x productivity increase for designing complex SoCs is needed. The main factor predicted to help
achieving this goal is the use of IPs (third party or re-use of previously used components). ITRS estimates that at around 90%
of the SoCs will be composed of IP components. Having relinquished so much control for economic reasons opens the debate to how
trustworthy the HW systems actually are. This is especially the case for mission-critical applications, because these applications
should be extremely secure, but typically only about one to two percent of the global ICs target these applications. Although
a fraction of the total IC market, they are essential to national security, but is economically infeasible to have a separate
supply chain for them. In this project we address the issue of HW trustworthiness from the behavioral-level intellectual
property protection (IPP)point of view.
Key References:
J. Chen and B. Carrion Schafer,
Thermal Fingerprinting of FPGA Designs through High-Level Synthesis, ACM Great Lakes Symposium on VLSI (GLSVLSI), pp. 1-4, 2019.
B. Hu, J. Tian, M. Shihab, G. R. Reddy, W. Swartz Jr., Y. Makris, B. Carrion Schafer, C. Sechen,
Functional Obfuscation of Hardware Accelerators through Selective Partial Design Extraction onto an Embedded FPGA, ACM Great Lakes Symposium on VLSI (GLSVLSI), pp. 1-6, 2019.
N. Veeranna and B. Carrion Schafer,
Efficient Behavioral Intellectual Property Source Code Obfuscation for High-Level Synthesis, 18th IEEE Latin American Test Symposium, Bogota, Colombia, 2017.
N. Veeranna and B. Carrion Schafer,"
Trust Filter: Runtime Hardware Trojan Detection in Behavioral MPSoCs", Journal of Hardware and Systems Security, Springer, 2017.
N. Veeranna and B. Carrion Schafer,"
Hardware Trojan detection in Behavioral Intellectual Properties(IPs) using Property Checking Techniques", IEEE Transactions on Emerging Topics in Computing, 2016.
X. Li and B. Carrion Schafer,
Temperature-triggered Behavioral IPs HW Trojan Detection Method with FPGAs, FPL, September, 2015
[pdf].
Resources:
Synthesizable SystemC designs with Hardware Trojan of different trigger and payload mechanisms. Available at:
[Resources web page].
C-Based HW/SW Co-design
Ongoing • 2013-present•
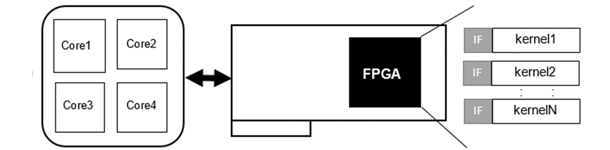
Heterogeneous system have been proposed as computing paradigms to keep up with this increasing computational power demand. These
systems comprise CPU(s) and HW accelerator(s) to execute certain parts of the applications more efficiently. These heterogeneous
systems can be Multi-Processor SoCs (MPSoC) combined with HW accelerators built around fixed logic or reconfigurable IPs embedded
onto the MPSoC, or at a different level, traditional CPUs augmented with FPGAs. These latter systems are sometimes called
Dataflow Engines (DFE), and stream data from memory onto the FPGA where the operations are performed in wide, deep pipelines.
The entire computational flow is laid out spatially on the FPGA and hence large speed-ups compared to traditional processor
based system can be normally achieved for the right kind application.
In parallel to the advances in computing power, the Electronic Design Automation (EDA) industry has also advanced significantly.
In particular, the industry has addressed the increase in design productivity needed in order to allow designers to make use
of all the transistors available to them. This has been mainly accomplished by raising the level of abstraction. One of these
new technologies is High-Level Synthesis (HLS). HLS synthesizes behavioral descriptions in high-level languages (e.g. ANSI-C/C++ or Matlab)
and creates the RTL code (VHDL or Verilog) that can in turn be used to configure FPGAs. Because most of the simulation models for
computationally intensive applications are written in high-level languages it makes sense to investigate direct paths between pure software
(SW) descriptions and a HW-accelerated version. In this HW-accelerated version, the most computational intensive kernels of the SW description
are mapped onto an FPGA, while the rest will be executed on the CPU. Moreover, because the size of the FPGAs have increased significantly,
it is now possible to map multiple applications onto the same device.
Key References:
S. Xu, S. Liu, Y. Liu, A. Mahapatra, M. Villaverde, F. Moreno, B. Carrion Schafer,
Design Space Exploration of Heterogeneous MPSoCs with variable Number of Hardware Accelerators, Microprocessors and Microsystems, Springer, Vol. 65, pp.169-179, 2019.
Y. Liu and B. Carrion Schafer,
Optimization of Behavioral IPs in Multi-Processor System-on-Chips, ASP-DAC, pp. 336-341, Macao, 2016.
Y. Liu and B. Carrion Schafer,
Adaptive Combined Macro and Micro-Exploration of Concurrent Applications mapped on shared Bus Reconfigurable SoC, ESLSyn,San Francisco,2015.
High-Level Synthesis Design Space Exploration
HLS DSE Ongoing • 2007-present •
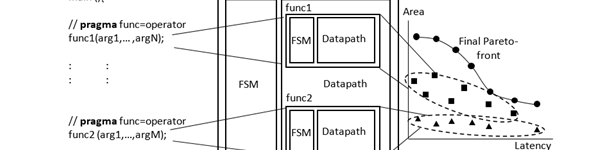
The main objective in design space exploration (DSE) is to findnd optimal implementations with respect to several, often conflicting, objectives, e.g. area,latency,
throughput, power. These optimal implementations are called Pareto-optimal designs. The objective is to find all the designs at the efficient frontier also called Parreto front. The trade-offs can easily be explored within this set rather than considering the entire design space, which would be impractical and irrelevant to the designer. The main problem in DSE is its exponential nature. A brute force approach would eventually findnd all the Pareto-optimal solutions for smaller designs at a cost of extremely high running time. Heuristics need to be developed to reduce runtime and find the best possible solution. These designs found by the heuristics
are called non-dominated designs as they dominate the exploration result obtained so far, but not the overall exploration space.
Key References:
Z. Wang and B. Carrion Schafer,
Partial Encryption of Behavioral IPs to Selectively Control the Design Space in High-Level Synthesis, Design, Automation, and Test in Europe (DATE), pp.1-4, 2019.
B. Carrion Schafer,
Parallel High-Level Synthesis Design Space Exploration for Behavioral IPs of Exact Latencies, ACM Trans. Design Autom. Electr. Syst. (TODAES), 2017.
B. Carrion Schafer,
Probabilistic Multi-knob High-Level Synthesis Design Space Exploration Acceleration, IEEE Transactions of Computer Aided Design (TCAD), Vol. 35, No.3, pp. 394-406, March 2016.
B. Carrion Schafer and K. Wakabayashi,
Machine Learning High Level Synthesis Design Space Exploration, IET Computers & Digital Techniques 6(3), pp. 153-159, 2012.
[pdf]
B. Carrion Schafer and K. Wakabayashi,
Divide and conquer high-level synthesis design space exploration, ACM Trans. Design Autom. Electr. Syst. 17(3): 29, 2012.
[pdf]
B. Carrion Schafer and K. Wakabayashi,
Design Space Exploration Acceleration through Operation Clustering, IEEE Transactions on Computer Aided Design of Integrated Circuits and Systems (TCAD), Volume 29, Issue 1, pp153-157, Jan. 2010.
[pdf]
Resources:
The following YouTube video shows an example of a HLS DSE explorer built in the lab using a Qt based GUI
[Video].
C/SystemC VLSI Design
Ongoing • 2007-present

Raising the level of abstraction has a distinct advantage over traditional register transfer level (RTL)
design approaches. Multiple designs can be easily and quickly generated for the same source code,
while RTL designs require major rework in the source code in order to modify the architecture.
All the hardware designs done at our department are implemented using HLS from C or SystemC as the input language (as much as possible) in order
to benefit form this new VLSI methodology shift. We use tools like CyberWorkBench.
to design entire SoCs at the C-level. Our department has also created a Synthesizable SystemC Benchmark (S2CBench) suite freely available for downlaod online at
S2CBench.
Key References:
B. Carrion Schafer, A. Trambadia, K. Wakabayashi, "Design of Complex Image Processing Systems in ESL", ASPDAC, Taiwan, Pages 809 - 814, 2010. [pdf]
B. Carrion Schafer and A. Mahapatra "S2CBench:Synthesizable SystemC Benchmark Suite for High-Level Synthesis", 20th meeting of the North American SystemC Users Group,2014 [pdf]
Resources:
The latest version of the S2Cbench benchmarks can be found at our resources web page
[Resources web page].
Thermal-aware VLSI Design
Ongoing • 2006-present•
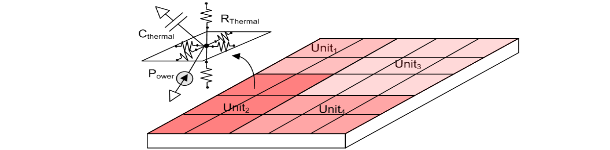
Temperature has an adverse effect on multiple aspects. It
affects the lifetime of the integrated circuit by accelerating
the chemical process taking place inside of the chip following
Arrhenius equation. Studies show the mean time between
failure (MTBF) of an IC is multiplied by a factor 10 for
every 30C rise in the junction temperature. Secondly
leakage power is becoming the dominant source of power
consumption for new process technologies which grows
exponentially with temperature. Moreover, temperature has a
negative effect on carrier mobility and therefore switching
speed of the transistors and thus the overall timing of the
circuit. Specially global signals like the global clock tree suffer
increased clock skew. Consequently it is highly desirable
to have an even temperature distribution on the chip in order to
avoid costly re-design due to timing/temperature and simplify
the verification phase. Furthermore, expensive heat dissipaters
are required to maintain the chip at a reasonable temperature
or could not be used in case of embedded system. Studies
have reported that above 30-40 Watts (W), additional power
dissipation increases the total cost per chip by more than $1/W.
Temperature is highly dependent on power consumption but
depends on a multiple of other factors, making power alone
not a valid measure for temperature. Temperature also depends
on the placement of the units in the chip. Placing heavy power
consuming units close together will intuitively generate an
even higher temperature area in the chip as temperature is
additive in nature. In contrast, placing power consuming units
close to units that have a moderate power consumption will
allow the heat generated to dissipate through these units. Other
aspects that affect temperature are the execution order of tasks
in a unit. Executing tasks one after the other will help the
temperature build up whereas spacing the execution of tasks
in a unit will allow the unit to have a time to prevent it from
heating up. Consequently, temperature should be addressed as
an individual design parameter [poster overview].
Key References:
B. Carrion Schafer and Taewhan Kim, Temperature Reduction in VLSI Circuits through Logic Replication, IET Computers & Digital Techniques, Volume 3, Issue 1, pp 62-71, January 2009.
B. Carrion Schafer and Taewhan Kim, Hotspots Elimination and Temperature Flattening for VLSI Circuits, IEEE TVLSI, Volume 16, Number 11, pp 1475-1488, November 2008. [pdf]
B. Carrion Schafer, Y. Lee and T. Kim, Temperature-Aware Compilation for VLIW Processors, 13th IEEE International conference on Embedded and Real-Time Computing Systems and Applications (RTCSA 2007), pp 426-431, Daegu, Korea, 2007. [pdf]
HW Acceleration of Numerical Intensive Applications
Past • 1999-present

As the complexity of Field Programmable Gate Arrays
(FPGAs) is continuously increasing, and entire
system can now be implemented on them with minimal
off-chip resources, they provide an ideal platform for
hardware acceleration. They can be configured to form
co-processors to perform custom hardware acceleration.
For the right type of application they can rival expensive
multi-processor systems that are normally used for such
purposes. FPGAs thus open a new window to low cost hardware acceleration.
Key References:
M.R. Babu, F. N. Taher, A. Balajandran and B. Carrion Schafer, Efficient Hardware Acceleration for Design Diversity Calculation to mitigate Common Mode Failures, IEEE International Symposium On Field-Programmable Custom Computing Machines (FCCM), pp.1-4, 2019 (accepted or publication).
B. Carrion Schafer, S.F Quigley, A.H.C Chan, Acceleration of the Discrete Element Method on a Reconfigurable Computer" Computers and Structures, Volume 82, Issues 20-21, pp 1707-1718, August 2004. [pdf]
B. Carrion Schafer, S.F Quigley, A.H.C Chan, Scalable Implementation of the Discrete Element Method on a Reconfigurable Computing Platform, 12th International Conference on Field Programmable Logic and Applications (FPL), Montpellier, 2002, Springer-Verlag .
Resources:
Hardware accelerated SystemC benchmarks. Available at:
[Resources web page].

